One of our long standing clients has just given us with the task of moving over 1.5TB of files and documents stored in Rackspace’s Managed Hosting data centre to the cloud; namely Rackspace Cloud Files. Using a combination of .NET and a crafty use of Powershell we managed to move those files within the allotted time.
Cloud Files provides online object storage for files and media, delivering them globally at blazing speeds over a worldwide content delivery network (CDN). You can store as many files as you want—even very large files.
We were moving from one Rackspace data centre to another in the same city; namely London. You would think that would be a simple task, but sadly it wasn’t. Rackspace don’t currently offer a bulk import process in London, although they do so in the US and Sydney. So, our idea of copying everything onto an external drive and shuttling it across with a courier to the other side of London wasn’t going to work.
We had another problem as well though, in that we needed to update the database references for each file that was moved. We were left with little option but to move each file in turn, updating the database references as we went along changing the file references from the local SAN disk, to a URL in the cloud. We had ~12 million files to move.
In order to do this, we wrote our own .NET app that worked in the following way:
- Query the database for the next 100 files that haven’t been processed
- Get the file as a stream and upload it using Rackspace’s own Openstack.net code fork
- Update the database for the transferred files
- Repeat until no files are left
We decided to run this application on a single Cloud server to isolate it from the rest of our production servers. We tested the application and found that it had some odd bugs, mainly centered around openstack.net. The first was that the files transfers would sometimes just hang. We found that the reason for this was that the openstack.net has a hard coded 4 hour timeout. Thankfully openstack.net is open source and the code is on Github.
The second problem was more tricky. The application would run for a number of hours, and then something would go wrong in the transfer. This would then throw the following error:
[ProtocolViolationException]: Chunked encoding upload is not supported on the HTTP/1.0 protocol.After that, all subsequent requests would then also fail with the same error. Digging in the logged issues on Github we came across other people having the same problem with chunked encoding errors. Due to the wonders of open source, another Github user (@paulcarroll) had already issued a pull request, which hadn’t yet been merged. We were able to fork his fork, fix the timeout bug and fix the chunked encoding bug. After that our error rate remained as expected rather than spiking wildly as it had before.
Running the one application on one machine gave us an idea of how long it would take to transfer the files. It became obvious that one instance of the app was going to take far too long (1.5 years!) so we needed to up the run-rate. We had two choices. The first option was to invest more development time in making our application multi-threaded and involving some kind of message queue to stack up the jobs. The other way was to script it with Powershell.
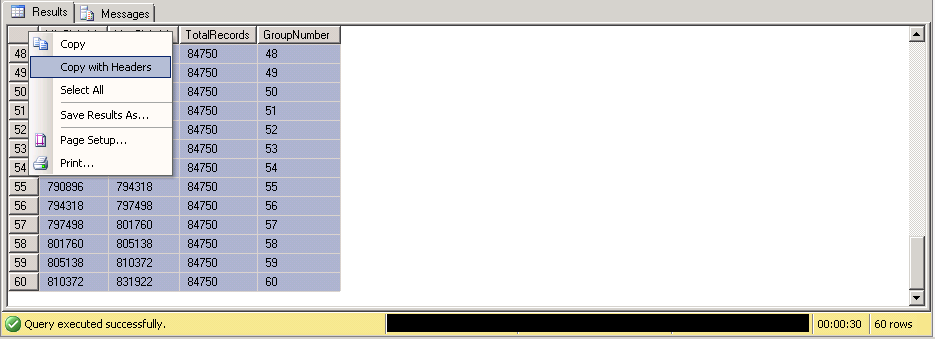
Powershell won. Each file that was being transferred was linked to a ‘job’ number. We decided to run multiple versions of the same executable as a Powershell ‘BackgroundJob’. We needed to split up all of the files into equal piles of ‘jobs’. To do this we turned to the wonders of SQL and the concept of ‘balanced sets’. The following query uses TSQL NTILE. It allows you to group results equally into a number of fixed buckets. We would then be able to designate a particular instance to only focus on jobs within their defined set. This would prevent any clashes between instances trying to work on the same job documents. A poor man’s queue as it were.
SELECT
MIN(JobId) AS MinJobId,
MAX(JobId) AS MaxJobId,
COUNT(*) AS TotalRecords,
GroupNum AS GroupNumber
FROM
(
SELECT JobId,
NTILE(60) OVER (ORDER BY JobId) GroupNum
FROM Attachment
WHERE TRANSFERED = 0
) AS IV
GROUP BY GroupNum
ORDER BY GroupNumThe results can be seen in the screenshot below:
Now we needed to use this in the Powershell script. We planned that our PS script would do something along the lines of the following:
- Load up a config file that defined each EXE instance install
- Unzip the source EXE and config into an instance folder
- Tweak the app.config for that instance (min job number and max job number)
- Run the EXE as a Powershell BackgroundJob
- Produce another PS script to kill all the running instances
The idea was that we could bring these multiple instances up and down and tweak them as an when we needed them. It also allowed us to run them on multiple machines if we needed to, though one machine delivered the result we needed in the end.
The first thing we needed to do was find a way to load a configuration file into Powershell. We needed a data format to store a list of instances, based on the SQL results from above. XML is so passé, so we wanted JSON. How do you convert SQL results to JSON? Mr Data Convertor, that’s how. You simply paste your SQL result set into the online app, and it converts in into JSON! Awesome.
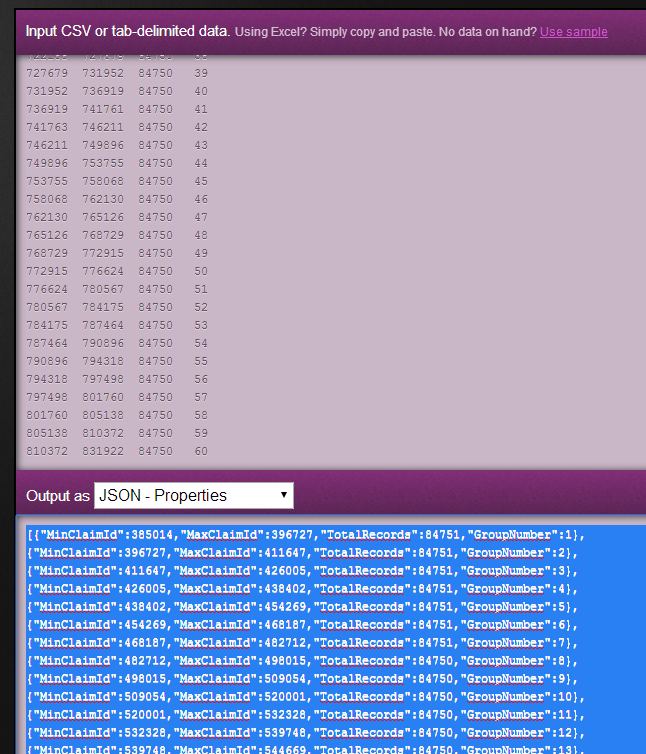
Now we paste the JSON output into our migration config file. Does Powershell load up JSON data. It sure does!
$installs = get-content install.json -Raw | ConvertFrom-Json | Select -ExpandProperty installsThis gets you a variable called $installs containing that JSON object, which in our case just happens to be an object list we can enumerate.
foreach ($i in $installs) {
# do magic stuff
}We now needed to copy over the source executable, update it’s config with its minimum and maximum job number (its working set), and kick off the process with a BackgroundJob. The following illustrates that process:
# work out the install folder name
$folderName = Join-Path $scriptPath ("appsapp_" + $i.MinClaimId + "-" + $i.MaxClaimId + "")
# copy the folder to the install
Copy-Item $source $folderName -recurse -force
# fiddle with the config (Edit-Config is an custom function see below)
$appConfig = $folderName + "TransferApp.exe.config"
Edit-Config -File $appConfig -MinValue $i.MinJobId -MaxValue $i.MaxJobId
# run it
$appPath = $folderName + "TransferApp.exe"
#echo $appPath
$block = {& $appPath}
#start-job -Name ("app_" + $i.GroupNumber) -scriptblock $block
# start the background job
start-job -Name ("app_" + $i.GroupNumber) -ScriptBlock { & $args[0] } -ArgumentList @($appPath)
To edit the config file, we need to work with XML in Powershell. App.configs aren’t JSON (yet).
function Edit-Config($file, $minValue, $maxValue)
{
$appConfig = [xml](cat $file)
$appConfig.configuration.migrateFilesSettings.SetAttribute("minClaimId", $minValue)
$appConfig.configuration.migrateFilesSettings.SetAttribute("maxClaimId", $maxValue)
$appConfig.configuration.migrateFilesSettings.SetAttribute("workHours", "")
$appConfig.Save($file)
}Now each instance (60) were configured and up and running. The Powershell script also created a kill script so we could bring down these instances quickly. We also tweaked the application to run out-of-work-hours so that it would not hammer the database during work time. Out of work hours it really did push the DB server to it’s limits.
The whole transfer process took around 22 days (running overnight except on weekends). We didn’t log statistics until a few days in. But once we did, we published them out to a Google spreadsheet that allowed us to track and predict finish dates. The spreadsheet can be seen here:
Because some of the files had been previously archived manually (but the database not updated to match) we knew we would have some genuine errors when source files didn’t exist. In the end we ended up migrating 6.75 million source files. In the case of images we also copied across the thumbnail images, or created them on the fly when we couldn’t locate the thumbnail adding to the 6.75 million source files we moved. We had 2.87 million genuine (expected) failures through 404s.
The files finished transferring one day before the old hardware was due to be turned off. The power of Powershell came into its own in this particular task, and I was surprised to find out that it supported such a variety of functions out of the box; Load up JSON data, extract ZIP files, run background jobs; the list goes on.
A very powerful tool for Windows devs and ops alike.